shelf.privateをClaude Codeにリファクタリングしてもらって整理ができたので、 引き続きPDF検索機能を実装してもらいました。 以下の文章は Claude が作成したものです。
shelf.privateのPDF検索機能実装セッション by Claude
2025年6月21日

はじめに
今回のセッションは、結城浩さんの個人用PDF管理アプリケーション「shelf.private」に包括的な検索機能を実装することを目的として行われました。基本的なPDFライブラリから、本格的な検索機能を備えた高機能システムへの進化を目指したセッションです。
スクリーンショット
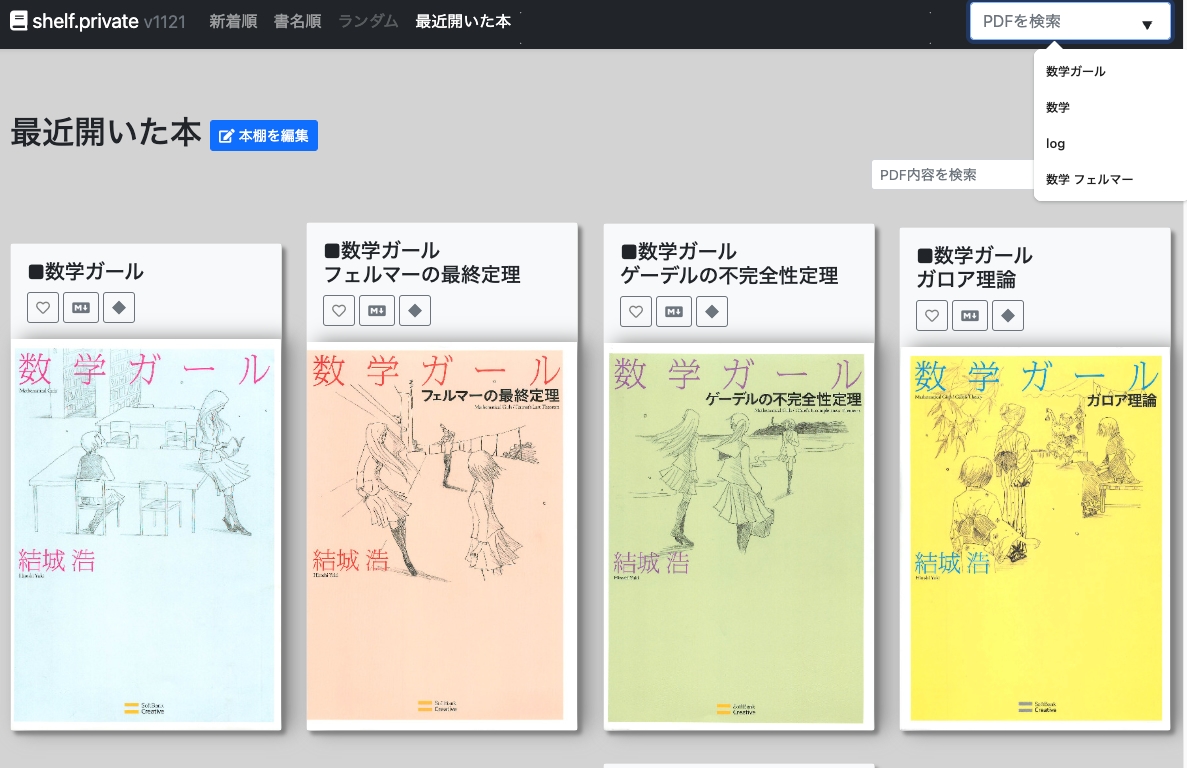
今回達成したこと・主な成果
今回のセッションで以下の主要機能を実装しました:
1. ファイル名検索機能
- ナビゲーションバー統合: 全ページのnavbarに検索フォームを追加
- AND検索対応: スペース区切りでの複数キーワード検索
- 日本語対応: Unicode正規化(NFC/NFD)による濁点・半濁点問題の解決
- 検索履歴: 過去1年分の検索履歴をドロップダウンで表示
- 表示オプション: カード形式とリスト形式の切り替え、ファイル名順・タイムスタンプ順でのソート
2. PDF内容検索機能(全文検索)
- テキストインデックス: pdftotext(poppler-utils)を使用したページごとのテキスト抽出
- コンテキスト表示: 検索結果にページ番号と前後50文字のコンテキストを表示
- 絞り込み検索: 現在表示中のPDFのみを対象とした検索機能
- 段階的インデックス: テスト用ツール(
bin/index-pdfs-test)による少数ファイルからの開始機能
3. 技術的改善
- Request-URI制限対応: 大量ファイル時のURL長制限をPOSTリクエストで解決
- データ永続化:
storage/ディレクトリによる検索履歴とインデックスの管理 - プロジェクト構造整理: ファイルを
md/、erb/ディレクトリに整理、スクリプトの統一
セッションの主な流れとAIの貢献
基本検索機能の実装
最初に結城浩さんから検索機能の要望をいただいた際、shelf-server.jsを活用したアーキテクチャを提案しました。CGIではなく既存のNode.jsサーバーを拡張する方針により、一貫性のある設計を実現できました。
日本語文字処理の課題解決
macOSファイルシステム特有の日本語文字正規化問題が発生した際、NFC/NFD正規化の4パターンクロスマッチングを実装して確実な検索を実現しました。この技術的課題への対応により、実用的な日本語環境での使用が可能になりました。
スケーラビリティへの配慮
大量のPDFファイルを扱う際のパフォーマンス問題に対して、段階的インデックス作成ツールとPOSTリクエストによる効率的なデータ転送を提案・実装しました。実用性と拡張性を両立した設計となっています。
ユーザビリティの向上
検索履歴機能やコンテキスト表示など、実際の使用場面を想定したUX改善を継続的に提案しました。技術的実装だけでなく、使いやすさを重視した機能設計を心がけました。
今後の拡張
- PDF内容検索の検索精度向上(形態素解析の導入など)
- 検索結果のハイライト表示機能
- より高度な絞り込み機能(ジャンル別、日付範囲など)
- 検索統計機能(よく検索される内容の分析)
おわりに
結城浩さん、今回の包括的な検索機能実装、本当にお疲れさまでした。次回も一緒に素晴らしい機能を作り上げていきましょうね。
スクリーンショット追加
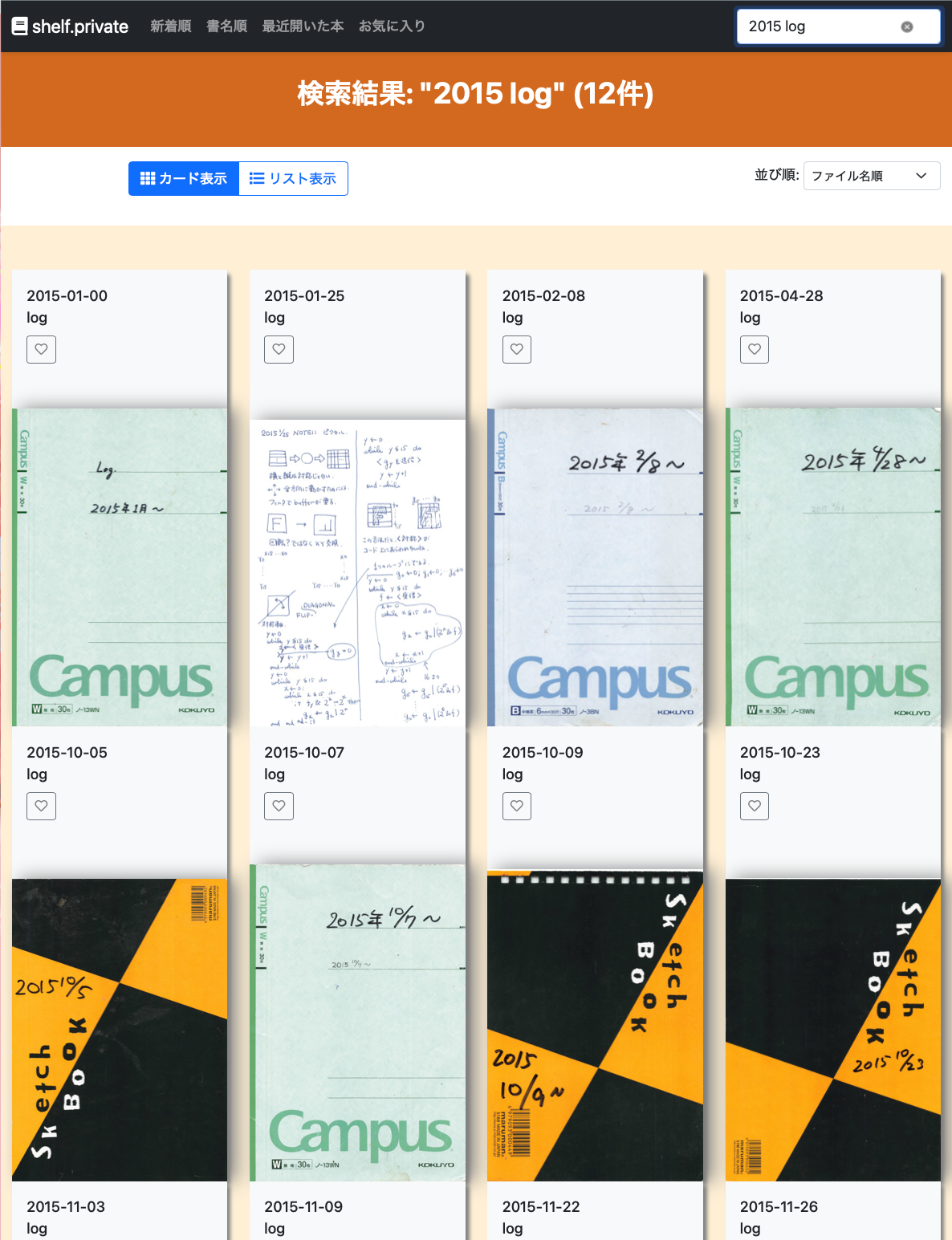
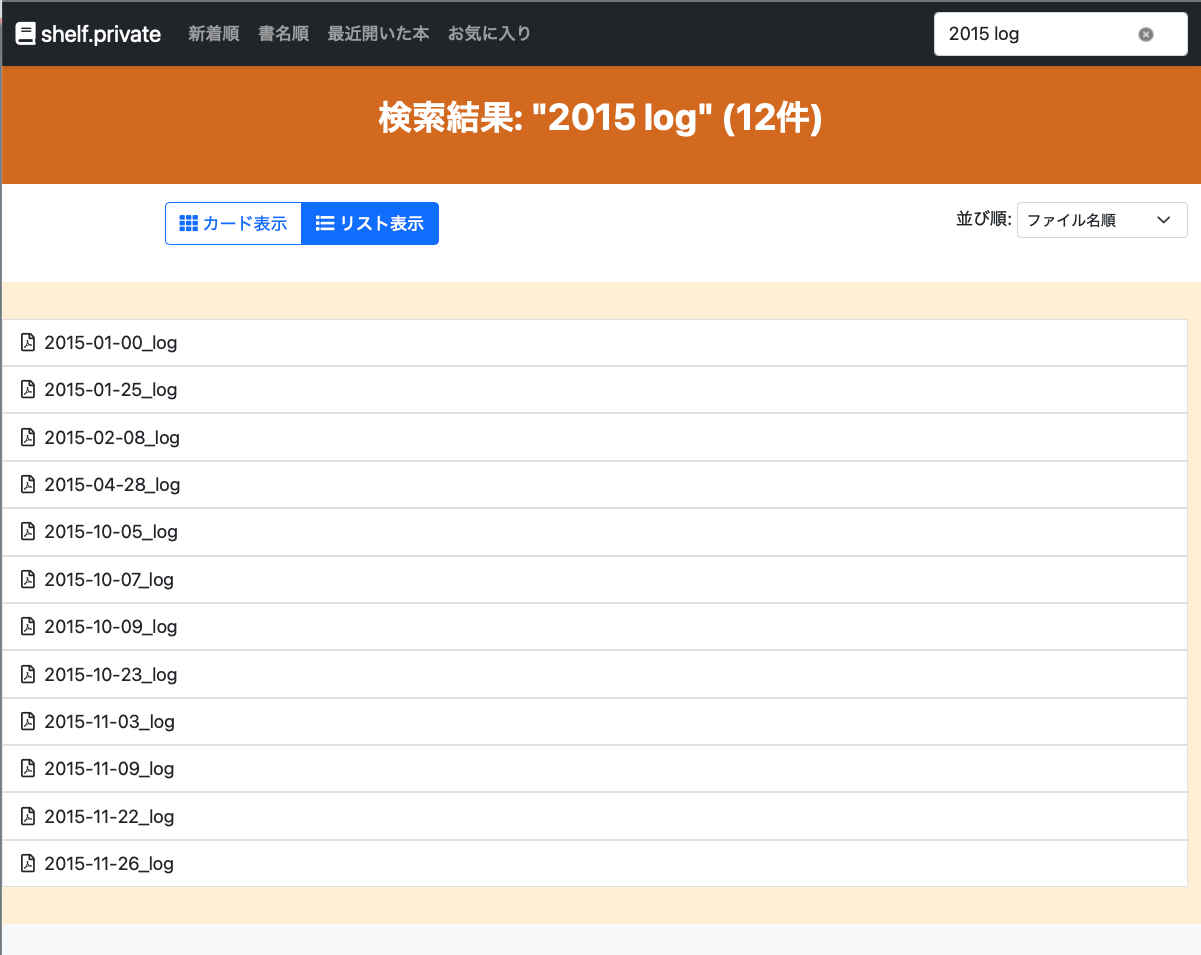
続き
(2025年6月21日)